


We’ve been hit with the same question from a number of customers recently: which High Availability (HA) methods for Microsoft SQL Server can work alongside PaperCut MF or NG?
Explaining what’s required to connect to an external database should be a pretty simple conversation, right? All we need is the address of the database, and a username and password for us to get connected.
As long as the platform’s stable, well-resourced, and the endpoint doesn’t change, what goes on behind the scenes doesn’t really matter to PaperCut.
But if a customer wants to go beyond mere implementation, and figure out which HA method for SQL is truly the best for their business, the process can be a doozy. Cue the hopefully-helpful mass of text below!
Backups, downtime, and the importance of HA
Following on from our HA Whitepaper and Server Sizing Guide , which focus on the Application Server, I’m going to drill down into the HA options available within Microsoft SQL Server to hopefully set you up to have some high-level chats with customers.
As you’ll see, there’s no one-size-fits-all method, and there are pros and cons to every option. At the end of the day, the decision has to sit with your customer.
When a customer brings an SQL server online, it begins running databases – the PaperCut database, in our case. A customer’s printing system could be crucial, so they need to know the database isn’t going to let them down.
It’s likely that they’ll want to do whatever they can to keep the database online, healthy, and available to accept connections from PaperCut MF or NG – which all leads to maximum uptime.
But achieving that goal of HA inside Microsoft SQL is challenging. How can a customer make sure their databases are always online and healthy? How can they plan for a multitude of different disasters?
You’re probably already aware of the recommendation to make backups. If your customer has a backup and their server fails, gets destroyed, or something similarly horrible, they can restore it somewhere else.
The problem is that doing this takes time – and downtime’s unavoidable if you’re relying on backups.
That being said, customers should still make backups, as they’re a great final line of defense. But there are a few other methods we’ll run through to minimize the amount of downtime, or even eliminate it altogether if they have a physical server failure.
Never miss an update!
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Different HA methods explained
Each HA method has its unique place, and provides a certain level of resiliency. Just because database clusters are awesome, doesn’t mean everyone needs them.
Your customer needs to look at their needs, their environment, and figure out which method will work best for them. So let’s get stuck in.
1. Replication
Let’s start with a feature which often comes up in the discussion: the replication feature within Microsoft SQL Server.
It works by syncing specific tables and objects (views, stored procedures, etc.) to one or more SQL servers – which sounds perfect on paper.
However, replication usually gets crossed off the list pretty quickly as it doesn’t provide the automatic failover (no one wants to come in at 2am on a weekend to switch over to a backup), which is one of the key requirements of a highly available database method.
Replication can also lead to differences between copies, which can lead to a number of problems, like user credit top-ups going missing. Not to mention, it was never really designed for HA.
2. Log Shipping
Okay, let’s get the obvious out of the way… It’s a pretty dumb name. But it kinda makes sense.
Rather than just copying actual database objects like tables and stored procedures, it uses the transaction logs (these record everything that happens in the database) as a source of information, ships everything over, and writes to the one or more Secondary SQL Servers.
Shipping happens at scheduled intervals. The default is every 15 minutes, but customers can adjust this, going to the extreme of syncing every minute, or extending out to as long as a whole day between syncs.
However, there are substantial overheads in shipping logs – and weighing this against how much information is acceptable to lose in a database outage can be a complex decision (and probably one to be made by the customer’s database administrator).
Much like Mirroring and Always On Availability Groups (Availability Groups) that we’ll dive into next, you can use Log Shipping to maintain one or more warm standby databases for a single production database.
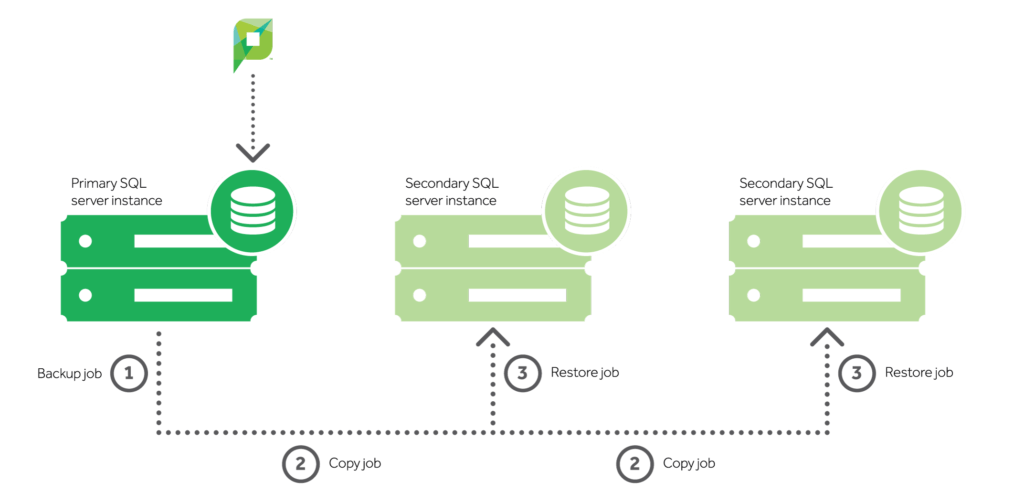
This provides a disaster-recovery solution, but switching over to one of the secondary SQL instances in the event of a failure isn’t automatic. Rather, a customer would need to jump into the PaperCut configuration, point to the secondary database, and restart the application server – which is all outlined here .
3. Mirroring
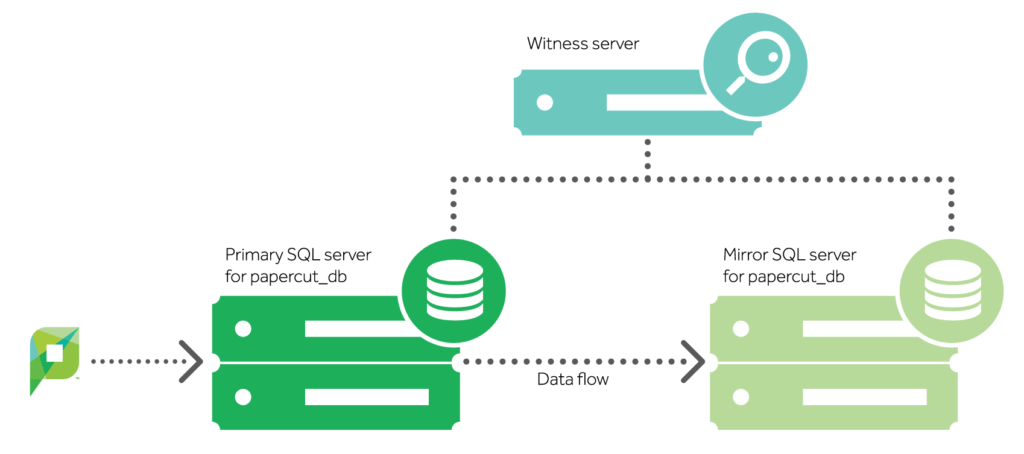
Mirroring is the first method which fits in with the goal of making a Microsoft SQL database highly available. It works by maintaining two copies of a single database that reside in different instances of SQL Server.
These are often spread across different data centers or geographical locations to protect against failures and everything burning to the ground, so to speak (but also not so to speak – we actually had a customer whose building burned down).
One of the two instances serves requests from the application (so, requests from PaperCut), while the other acts as a warm standby server ready to take over at a moment’s notice.
Running these databases in a high-safety mode makes sure the data is always exactly the same in both databases, with transactions being written to both databases at the same time before a response can be sent back to PaperCut.
Mirroring also supports failover without a loss of data via a witness server. This is a separate Microsoft SQL server that monitors the primary instance, and ensures a smooth switchover in the event of a disruption.
If the instances become disconnected from each other, they rely on the witness to make sure only one of them is currently communicating with PaperCut.
Having exact copies of the database always available and online allows a customer to manually switch the system over – without PaperCut realizing anything’s happened.
It might seem like the perfect solution, but it’s currently in maintenance mode, and could be removed in a future version of Microsoft SQL Server.
Because of this, Microsoft recommend skipping it for new installations, and making the switch to Availability Groups instead (which we’ll explore below).
4. Always On Failover Clustering
If you’ve ever had a conversation with a customer about clustering their PaperCut Application Server , then you’re in good stead to understand Always On Failover Clustering in Microsoft SQL Server.
For those that haven’t, clusters do something pretty awesome: they take something like the customer’s SQL server and separate it from the hardware it’s running on.
A running application is made up of two pieces: the pieces in RAM (anything cached, and any ongoing queries) and the hard drives (the databases).
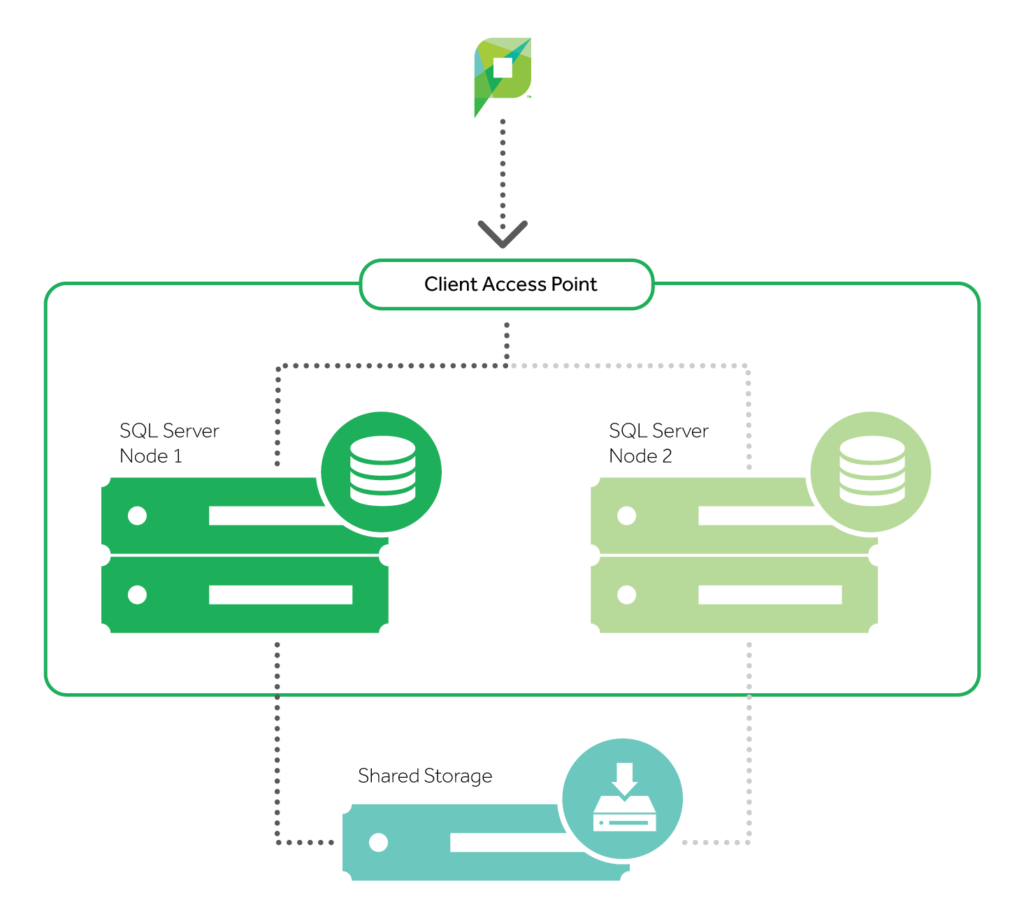
If a customer could take those hard drives and share them between more than one computer, then they could take their SQL server, and easily bring it up on new hardware at a moment’s notice. And that’s exactly what clusters lets you do.
With a clustered environment, you can have more than one server configured to use the same set of shared hard drives. Only one server will actually be using those hard drives at a time.
If a customer has a component failure, and that physical server goes down, they’ve got an entire second physical server standing by to grab the shared hard drives and get to work. And that results in the one thing we all love: little downtime.
On top of being super handy for failures, clusters are also really great for regular ol’ maintenance. For example, say a new service pack comes out for SQL and the customer wants to apply it. To do this, they have to stop the service and take the databases offline.
But what’ll happen to their end users when they do this? They won’t be able release their print jobs because PaperCut gets kicked out of the database. No good.
So to avoid this, they schedule the application for 3am on a Saturday morning, or something equally silly like that – which means coming into the office at that time. And nobody wants to do that. That stinks.
But with a cluster, the customer can circumvent this all together – thanks to two or more servers at their disposal.
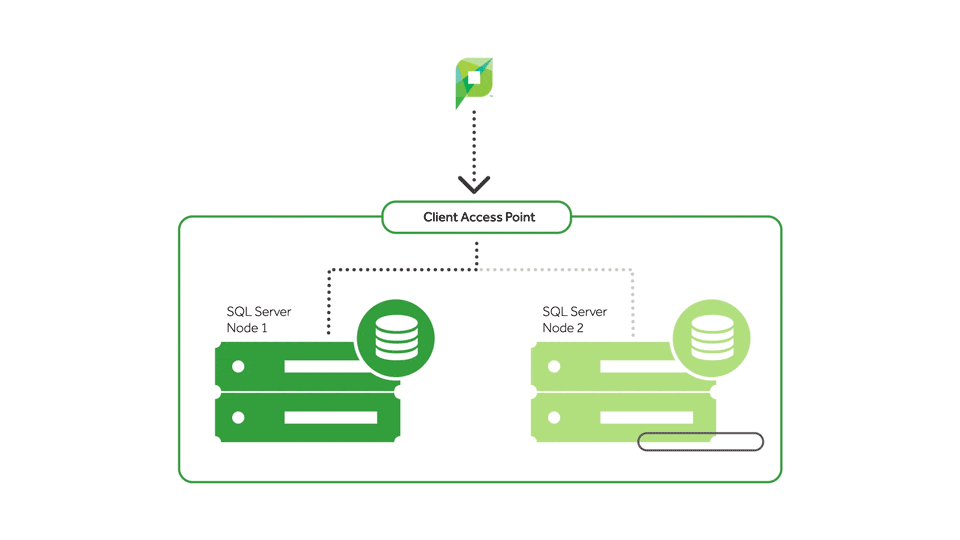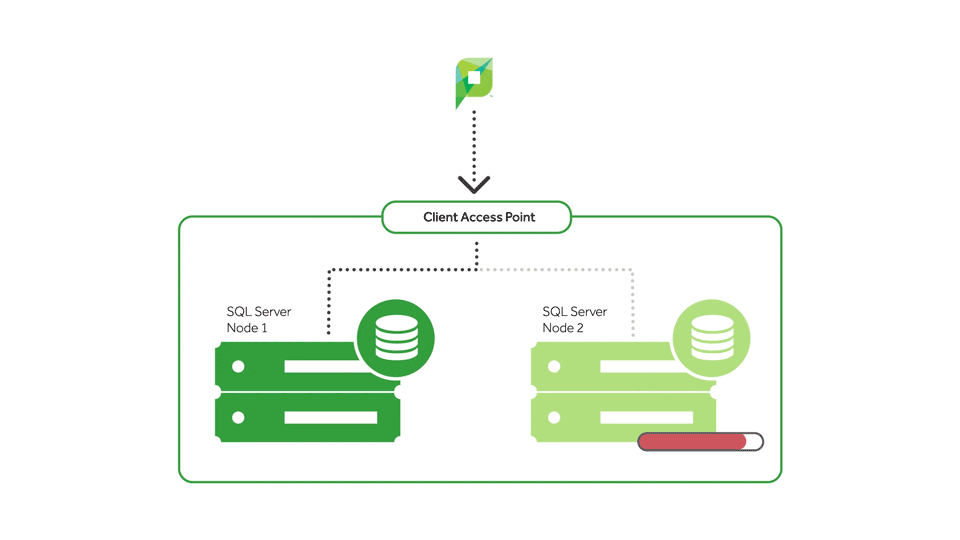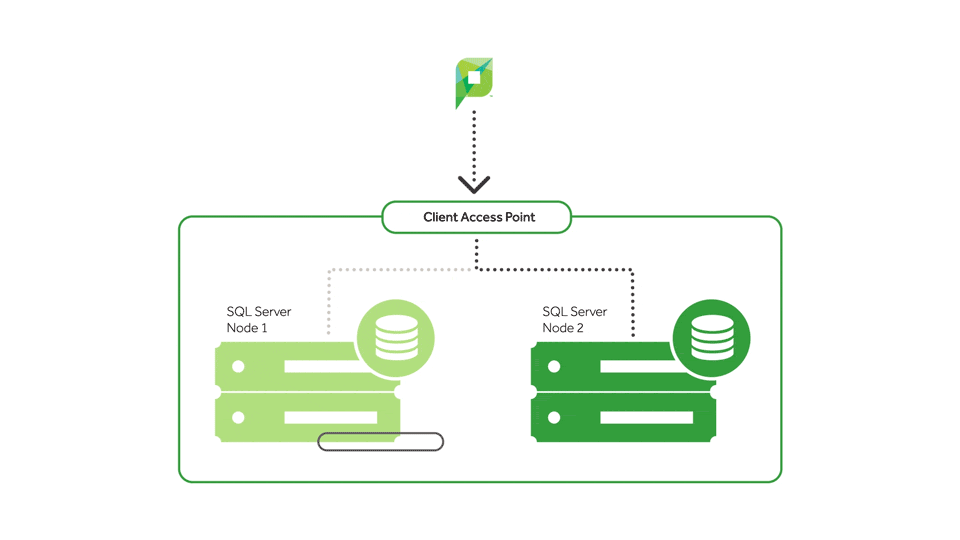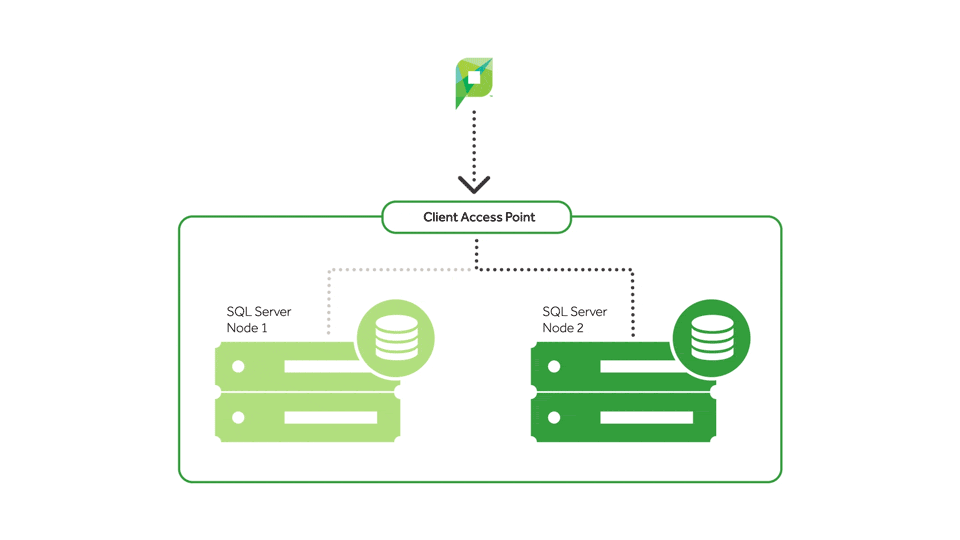
So server A can run SQL, and server B – just sitting there as a standby, not doing much – can have the service pack applied to it. They can then take their SQL server, fail it over, and apply the update to it. Both servers have been updated, and the end users were never kicked out. Magnificent.
That’s all well and good, you say. But it’s been like 10 paragraphs, and you’re yet to hit us with the inevitable drawback. We know it’s coming, Matt. Just lay it on us.
Fine. The biggest negative of clusters is simply cost. For one, it introduces a second server, so costs double – and then some – because hard drives need to be shared between the two servers. So that’s the number one reason not to do clustering: it’s super expensive. Happy?
It may be better for the customer to just accept the downtime when replacing the hard drive, rather than paying all this money to build a redundant infrastructure. After all, downtime hits different companies in different ways, financially speaking.
Plus, even if they do have a cluster, they’re still not immune to failure. Sure, they could have one entire server fail – and because the other server takes over, they don’t have to worry about the processor, memory, motherboard, power supply, and everything else that could fail.
But if your building burns down? Well, there go both of your clusters. Clusters need real-time communications, so you can’t sit each of them in two different geographic locations – they simply aren’t designed for that.
There are technologies that will let you do that, though – like geo-stretching. But there’s latency involved, which ism’t good for SQL Server.
So if the customer wants multiple geographic locations, they don’t want a cluster. They want one of the other technologies mentioned: Mirroring, Log Shipping, or Availability Groups (outlined below).
5. Always On Availability Groups
This last (hooray) method is a feature which was first introduced to SQL Server in 2012 to help customers maximize availability for one or more databases.
The Availability Groups feature is a HA and disaster-recovery solution that provides an enterprise-level alternative to Mirroring.
Like Failover Clustering, it depends on Windows Clustering, so it has a single unchanging point for PaperCut to connect to while the databases move around behind the scenes.
Unlike Failover Clustering, Availability Groups don’t need shared storage, which is especially important if a customer is looking to host in the cloud – and the cost savings should please their finance director.
Also, they don’t operate at the SQL instance level. Rather, they get right down to the individual databases, so it’s only the PaperCut database that’s moving between the SQL instances in the event of a failure.
Availability Groups replicate data much like Mirroring does. Customers can know their high-speed SSD storage is being replicated in near real-time to a warm standby server nearby, and to another in an entirely different country or region. Plus, they’re able to manually failover for patching. Bonus.
BUT (like you didn’t see that coming) setting up and maintaining Availability Groups isn’t just complicated – it comes at a substantial cost due to utilizing Microsoft SQL Server Enterprise, and requiring the customer to have one or more secondary servers online and idle, waiting for a failure to happen.
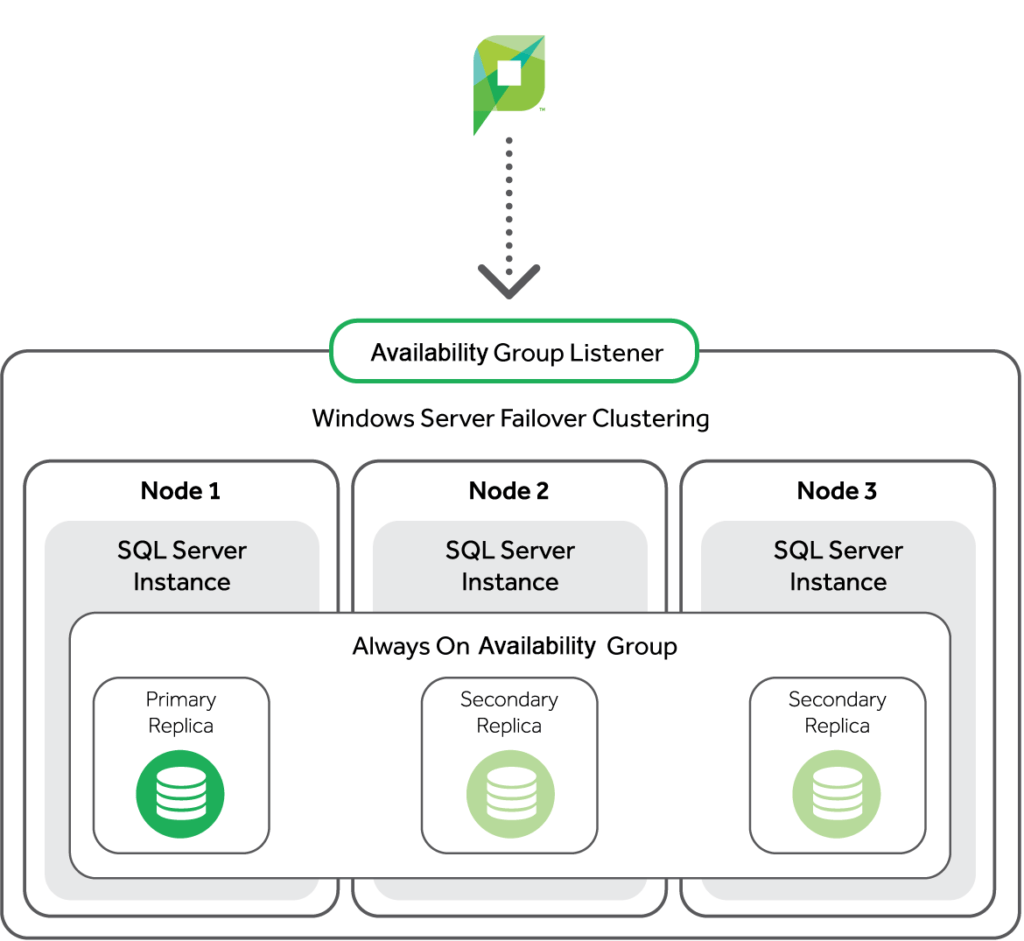
So, unless the specific use cases Availability Groups provide are critical – and the cost affordable – the investment and risk just aren’t worth it for most customers.
Wrapping up (finally)
I know, it’s a lot to take in. So where to from here? There are pros and cons to every HA methods for Microsoft SQL Server – be it the cost, complexity, or lack of automatic failover.
And these are all things your customer (and their Database Administrators) will need to consider to pick the best option – so I hope this article enables you to start some key conversations.
If you’re feeling daring and want to jump into more technical detail than what’s here, check out Microsoft’s helpful info on SQL HA methods .
Thanks!

